
From development to deployment: Distributed AI environments depend on HPE and Mellanox
-
Executive summary.
-
Overview
-
Benchmark results
-
Summary
-
System hardware and software components
Executive summary
When it comes to finding insight into massive amounts of both structured and unstructured data (images, text, voice, videos), machine learning is of principal importance for both research and business. Data analytics has become an essential function within many high-performance clusters, enterprise data centers, clouds, and hyperscale platforms.
Figure 1. Machine learning leverages vast amount of data to unlock actionable insights to drive new opportunities for a broad range of business and research applications
Overview
Using HPE Apollo 6500 systems, an industry-leading platform, state-of-the-art NVIDIA GPUs take advantage of Mellanox InfiniBand, supporting GPUDirect™ RDMA (GDR) and accelerate training neural networks when scaling out deep learning (DL) frameworks, such as Caffe, Caffe2, Chainer, MXNet, TensorFlow, and PyTorch.
AI development and deployment to production provides faster time to revenue or cost reduction or quality improvements to the business; however, it can be complex and requires the right technology and methodology to be successful.
Hewlett Packard Enterprise provides a single source for both. Working closely with world-class partners, HPE delivers technology along with guidance from resources such as the HPE Deep Learning Cookbook and consultative services.
The solution: The following products are integrated as a combined solution.
The HPE Apollo 6500 Gen10 system is an ideal DL platform that provides performance and flexibility with industry-leading GPUs, fast GPU interconnects, high-bandwidth fabric, and a configurable GPU topology to match varied workloads. The HPE Apollo 6500 system provides rock-solid reliability, availability, and serviceability (RAS) features and includes up to eight GPUs per server, next-generation NVIDIA NVLink™ for fast GPU-to-GPU communication, support for Intel® Xeon® Scalable processors, and a choice of high-speed/low-latency fabric. It is also workload-enhanced using flexible configuration capabilities.

Figure 2. HPE Apollo 6500 Gen10 system
The HPE Apollo 6500 Gen10 system supports up to eight NVIDIA Tesla V100 SXM2 16GB or 32GB GPU modules. Powered by NVIDIA Volta architecture, the Tesla V100 is the world’s most advanced data center GPU, designed to accelerate AI, HPC, and graphics workloads.1 Each Tesla V100 GPU processor offers the performance of up to 100 CPUs in a single GPU and can deliver 15.7 TFLOPS of single-precision performance and 125 TFLOPS of DL performance, for a total of one PFLOPS when fully populated with eight Tesla V100 GPUs. The tested architecture leverages NVIDIA NVLink technology to provide higher bandwidth and scalability for multi-GPU configurations. A single V100 GPU supports up to six NVIDIA NVLink connections for GPU-to-GPU communication, for a total of 300 GB/s.

Figure 3. NVIDIA Tesla V100 GPU Accelerator
Networking: Mellanox EDR 100Gb/s InfiniBand
When GPU workloads and data sets scale beyond a single HPE Apollo 6500, a high-performance network fabric is critical for maintaining high-performance, internode communication, as well as enabling the external storage system to deliver full bandwidth to the GPU servers. For networking, Mellanox switches, cables, and network adapters provide industry-leading performance and flexibility for an HPE Apollo 6500 system in a DL solution.
Mellanox is an industry-leading supplier of high-performance Ethernet and InfiniBand interconnects for high-performance GPU clusters used for DL workloads and for storage interconnect. With such technologies as remote direct memory access (RDMA) and GPUDirect, Mellanox enables excellent machine learning scalability and efficiency at network speeds from 10 Gbps to 100 Gbps. The InfiniBand network provides a high-performance interconnect between multiple GPU servers as well as providing network connectivity to the shared storage solution.

Figure 4. Networking: Mellanox EDR 100Gb/s InfiniBand
Benchmark results
In this paper, we are testing the performance of distributed deep learning using Horovod. Horovod is one of the latest methods for optimizing distributed deep learning using a ring reduce methodology with NVIDIA Collective Communications Library (NCCL). Our testing mentioned in the following will examine result of Horovod over standard Ethernet (TCP) protocols and using Mellanox’s InfiniBand technologies. In the InfiniBand implementations, we compare the implementation with and without enabling of GPUDirect.
The following training was performed using ImageNet 2012 for both ResNet-50 and VGG16 models. This was to demonstrate scalable performance and efficiency by utilizing HPE Apollo 6500 Gen10 systems with NVIDIA Tesla V100 SXM2 16GB GPUs while providing comparisons of the scalability and performance advantages using Mellanox EDR 100Gb/s InfiniBand over that of 100 Gb/s TCP.
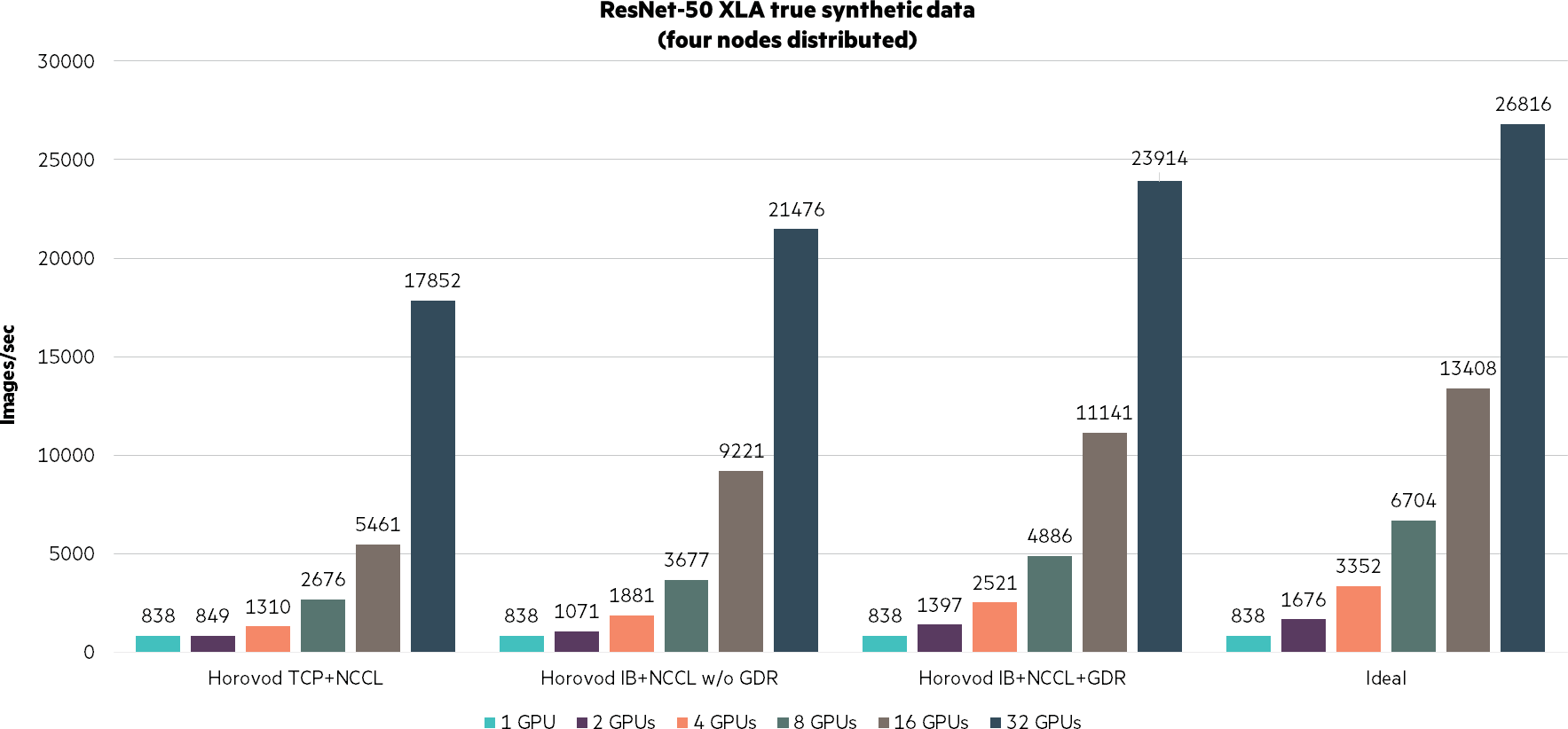
Figure 5. ResNet-50 XLA true synthetic data (distributed nodes).png
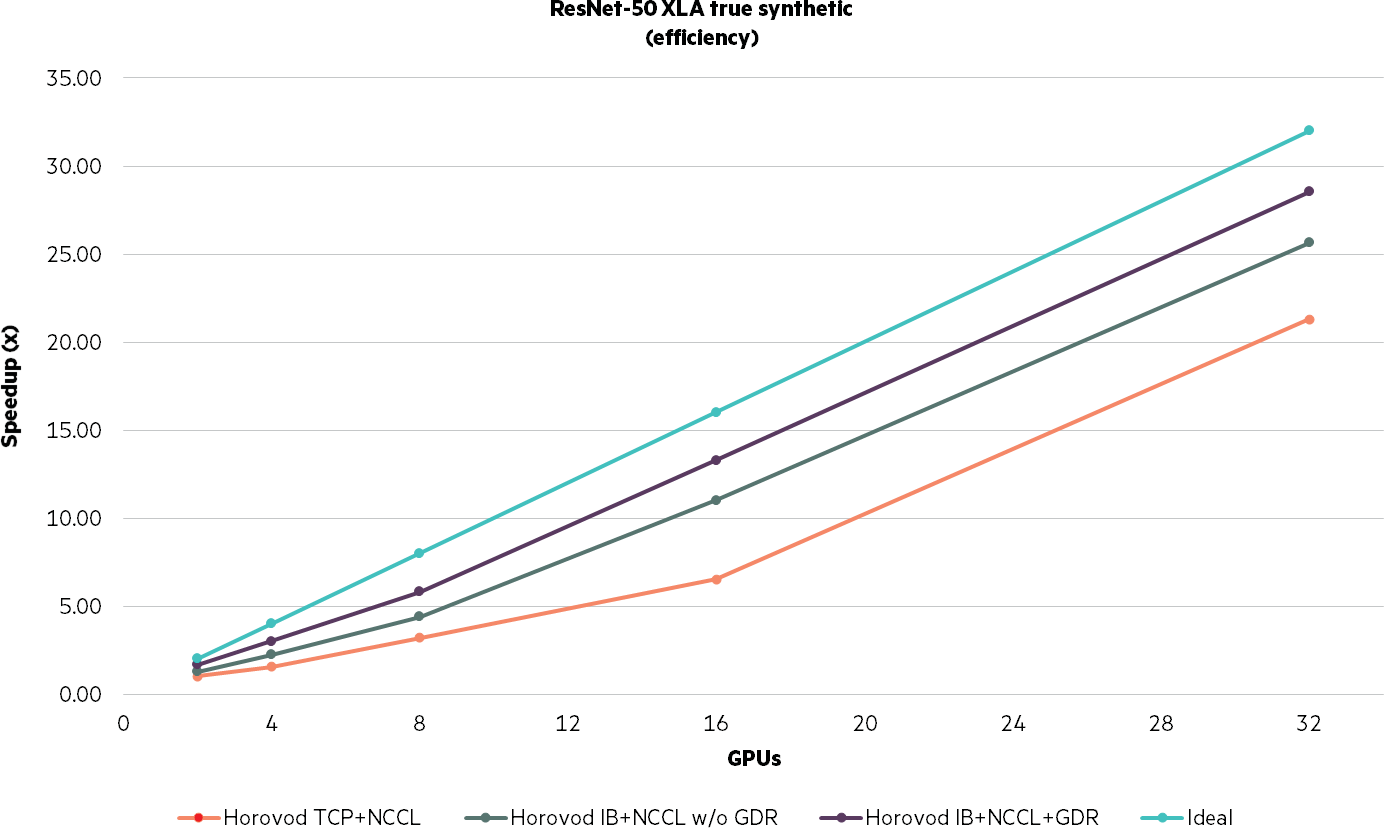
Figure 6. ResNet-50 XLA true synthetic (efficiency)
Key takeaway: With any distributed computing exercise, the efficiency is not a purely linear result—32 GPU are not 32X faster than one. Even inside a single HPE Apollo 6500 system, 8 NVLink enabled GPUs are not 8X faster than a single GPU, with only ~75% (4886/[8×838]) scaling efficiency in a single node of GPU with NVLink. Progress has been made in recent years on enabling distributed deep learning in an InfiniBand environment. As an example, consider the almost 90% scaling in our results with Horovod, InfiniBand, NCCL, and GPUDirect enabled above for 32 GPU versus a single GPU (23914/[32×838]).
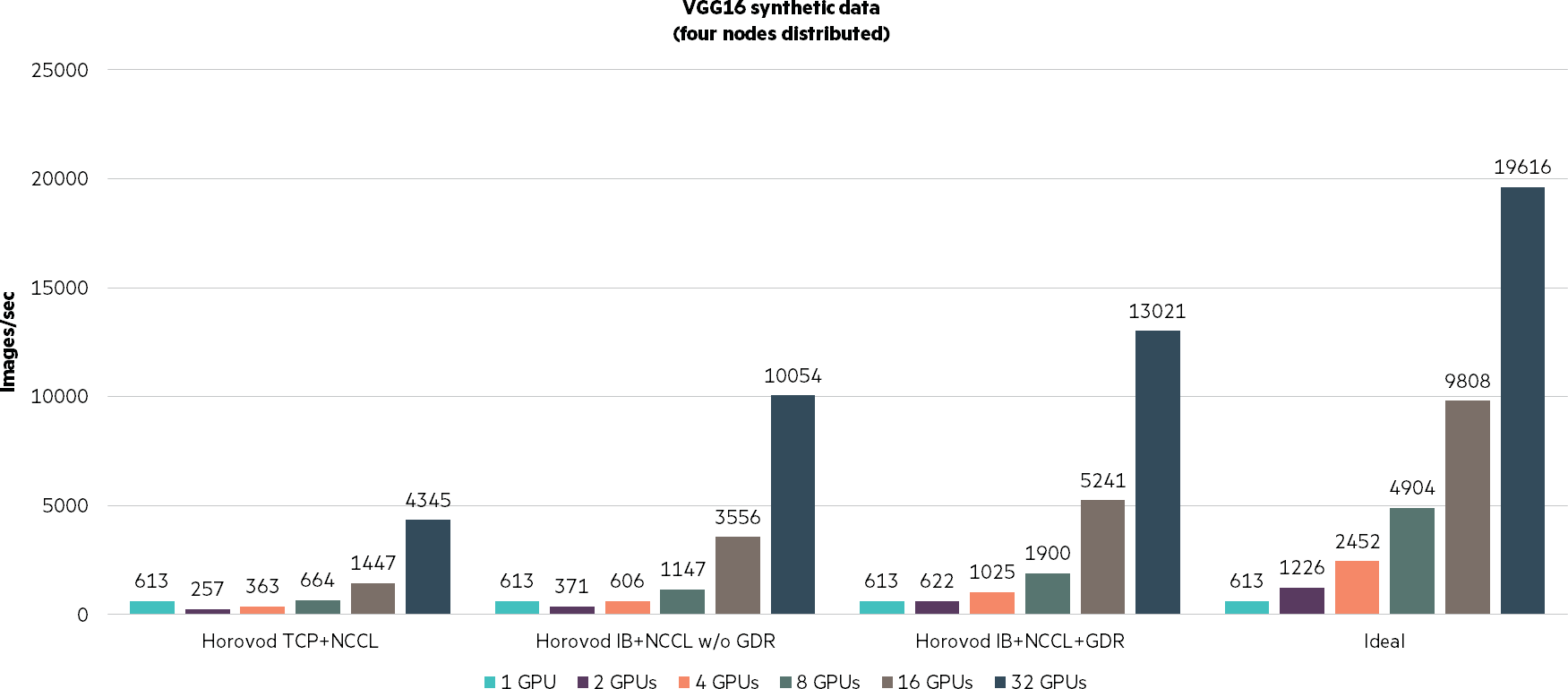
Figure 7. VGG16 synthetic data (distributed nodes)
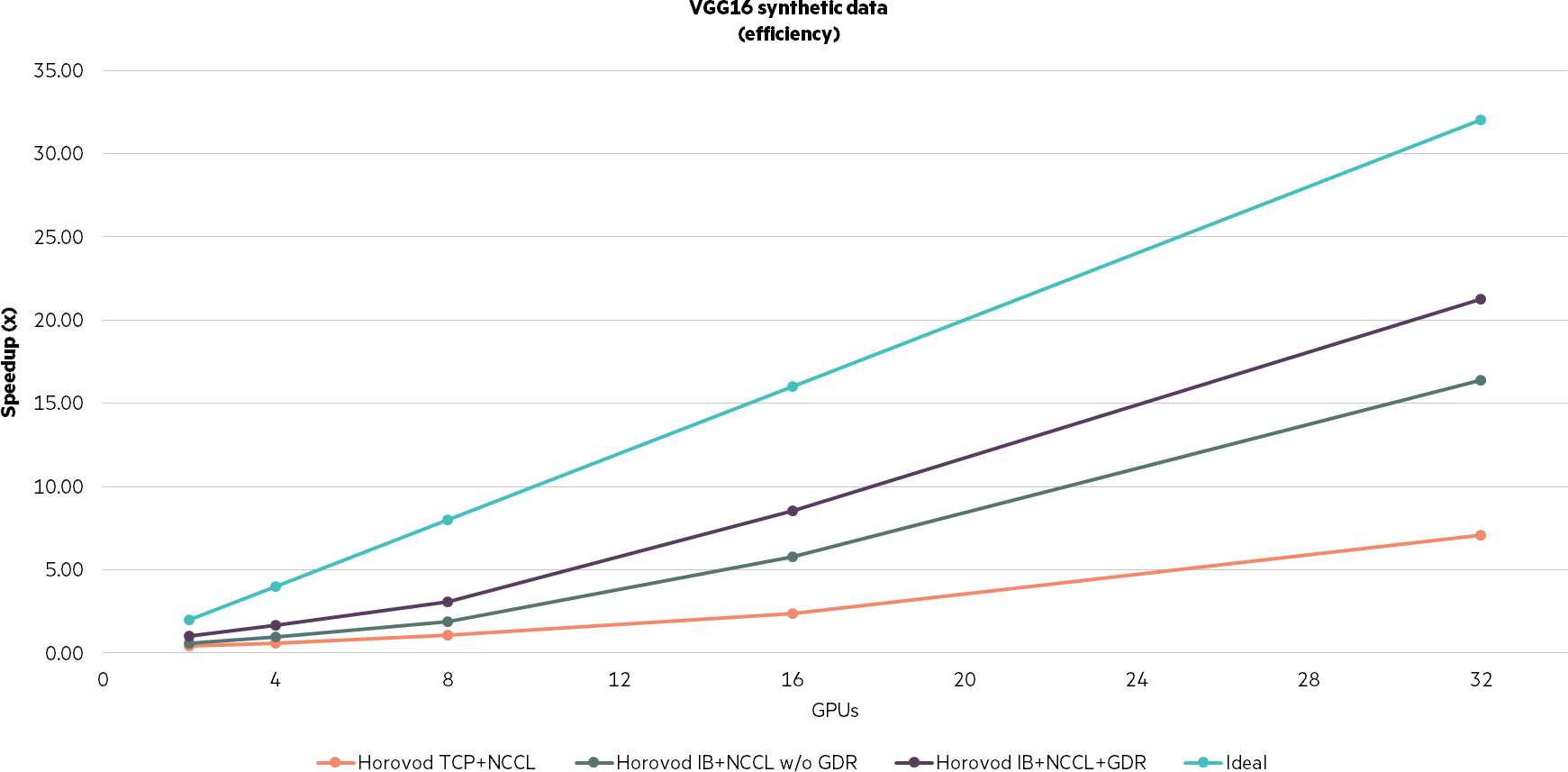
Figure 8. VGG16 synthetic data (efficiency)
Key takeaway: Again, consider the almost 90% scaling in our results with Horovod, InfiniBand, NCCL, and GPUDirect enabled previously for 32 GPU versus a single GPU.
Summary
By taking advantage of the advanced system hardware architecture of HPE Apollo 6500 Gen10 system with NVIDIA Tesla V100 SXM2 16GB GPUs and Mellanox EDR 100Gb/s InfiniBand smart interconnect, end users can expect between 1.3X and 3X or more performance improvement over that of 100 Gb/s Ethernet.2 Leveraging native RDMA, GPUDirect and advanced offload capabilities of the InfiniBand interconnect demonstrates the highest efficiency and scalable performance for AI workloads, delivering the highest data center return on investment and the fastest possible data insights
System hardware and software components
Four HPE Apollo 6500 Gen10 systems configured with eight NVIDIA Tesla V100 SXM2 16GB, two HPE ProLiant DL360 Gen10, Intel Xeon Gold 6134 (3.2GHz/8-core/130W) CPUs, 24 DDR4-2666 CAS-19-19-19 Registered Memory Modules, HPE 1.6TB NVMe SFF (2.5″) SSD, HPE InfiniBand EDR 100 Gbps 2-port 841QSFP28 Adapters, HPE Mellanox InfiniBand EDR 100Gb/sec v2 36-port Switch (SB7890), Ubuntu 16.04, MLNX_OFED 4.5-1.0, Mellanox OFED GPUDirect RDMA 1.0-8, Docker 18.09.1, CUDA SDK 10.0, TensorFlow 1.12, Horovod, TensorFlow Benchmarks v1.12 compatible.